Shortest Path Algorithm
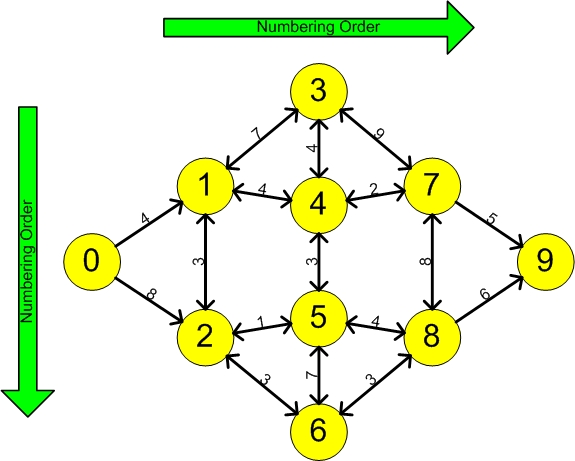
Fig. 1 Routes from location ‘0’ to destiny 9th (‘graph3.txt’)
Although human eye can understand the graphs above or might even
roughly guess out the shortest routes, but on the other hand computer can't. Therefore we need to convert all the locations from the
graphs to lists such as below so computer can recognize.
|
Node |
#1 |
#2 |
#3 |
#4 |
#5 |
#6 |
#7 |
#8 |
#9 |
#10 |
|
Connections |
#2 - 4 |
#3 - 3 |
#2 - 3 |
#2 - 7 |
#2 - 4 |
#3 - 1 |
#3 - 3 |
#4 - 9 |
#6 - 4 |
NA |
Table 1: Routes list extracted from Fig. 2

Fig. 2 Routes from location
‘0’ to destiny ‘29’ (‘1.txt’)
Before go to the main program, few
points need to be emphasized here. Route maps sketched by hand are unreliable,
in the sense that from the same routes list, we can product millions of
different shape route map graphs. Therefore, doing the path searching using the
graphs will mislead you. (except Country road maps)
Another point is Numbering is vital to the programs. Numbering is very
objective, depending on how people sketch their route map graphs. Therefore,
different people will produce their own Numbering. However bad Numbering will
dramatically increase the workload, and proper Numbering will minimize the job.
Graphs with numbering not only acted as labels, but also at
the same time ranking the nodes, define nodes' priorities. Hence, we can
construct a priority queue. Here, smaller numbering indicates higher
priority.
Always put Numbering direction x align with the direction
pointing from Starting Point to Destiny. Labeling for axis y can
be either clockwise or anti-clockwise. Hence, we can gradually search
from breadth circular to depth circular (imagine from inner core to outer
layers). In some cases, to simplify problems, we can treat them as
individual layers. We can do paths search either from source to
destiny or vice versa. That's mean the other way, start search from
destiny to source, just that in priority queue, bigger numbers
will have higher priority (depth to breadth). Orientation will be opposite
in this case. Overall, the method remains unchanged. Therefore, there will be
no different in term of computation efforts.
As mentioned, labeling are very objective. If you
think circular labeling are ineffective, you can just label the nodes
that you think are appropriate. Thus, alter the priority queue sequence at
your will. However, on the other hand, in the event of we are tackling
with the very big graph (e.g. world flight routes), simple visual checking
& labelling no longer work properly. Detail on how to label
nodes will be explained later.
All the edges are vectors. Therefore
weights can only be an absolute value. If not, the search program
will be trap inside the loop.
The worst-case scenario will be the shortest path always oppose axis xand y direction, which will
significantly increase the workload. Same nodes will be path searches again and
again (repeated). In an ideal worst case condition, running time
will be = n + (n-1) + (n-2) + ... + 1 = Si=1n
Therefore, proper Numbering is important.
In real world, most of the path problems are oriented. e.g.
traffic roads have single way or two-way, broadband connections
have faster download speed and slower upload speed.
Therefore, it is practical to define orientations to the arcs. Where
hereby we call it oriented graph or directed graph. There is a
difference between the above 2 cases, traffic roads problem is
a single edge problem, where vertices n to n' or the opposition
share the same weights. Broadband connection is a double edges problem,
vertices n to n' and the opposition don't share the same weights. However,
these don't matter. We treat all the problems as the all-pairs
shortest path problem.
The ideal case will be the search function only execute n
times, where n = total routes. Make sure to check whether the
routes are single way or two ways. Two ways that's mean there are 2
routes, and the search function will have to execute from the both nodes.
The sub-path of the shortest path itself is a shortest path. Hence, any
routes changes in the sub-path wouldn't affect the shortest path itself.
However, we still need to re-calculate all the 'Total Shortest Distance' (Since
the routes changed). That's mean, we need to do the search from that point
again (by pushing nodes back to the queue).
Programming
in Visual C++
1) First, we need to include necessary libraries
in our program
|
#include <stdio.h> #include
<iostream> #include <limits> #include <malloc.h> |
2) Include libraries to construct priority queue
|
#include <queue> #include
<vector> #include <deque> #include <list> |
3) Library <limits> included so that we can defined our Symbolic Constant
integer, INFINITY = 2147483647
|
#defineINFINITYnumeric_limits<int>::max( ) |
4) Library <malloc.h> for creating dynamic
memory allocation. Our Structure Definitions:
|
struct Graph {
int num_connections; // Number of node's edges or
nodes' connection
int shortestDistance; // Total shortest distance from
source to respective nodes
struct {
int weight;
// Weights of node's edge
int dest;
// The node where edge heading to
} edges[5]; }; typedef struct Graph graph; typedef graph *graphPtr; |
Hereby, presumed maximum number of edges' is up-to 5. Therefore
we can create our graph using our Structure Definitions:
|
graphPtr myGraph;
// create 'myGraph' pointer to store graph
data |
5) Find out how many nodes in the graph
|
int nodecount = 30 |
6) Initially, we define source's shortestDistance to
be 0. And all the other nodes' shortestDistance
to be infinity, representing the fact that we do not know any path leading to
those nodes. When the algorithm finishes, shortestDistance will
be the cost of the shortest path from s to v or infinity, if no such path
exists.
By the same time, we set all the nodes' previous path as infinity/no defined
yet. Therefore we set them '-1' to show that nodes
are not connecting to anything other nodes.
|
if(myGraph !=
NULL) { myGraph[i].prevPath = -1; |
7) For conveniences, store the Routes list in a file (.txt, .db). Retrieve it:
|
FILE *cfPtr;
if( (cfPtr = fopen("Fig2.txt", "r")) == NULL)
cout << "File couldn't be opened\n"
<< endl;
else {
//build the graph
for(i=0; i<nodecount-1; i++)
fscanf(cfPtr, "%d%d%d%d%d%d%d%d%d%d%d",
&myGraph[i].num_connections,
&myGraph[i].edges[0].dest, &myGraph[i].edges[0].weight,
&myGraph[i].edges[1].dest, &myGraph[i].edges[1].weight,
&myGraph[i].edges[2].dest, &myGraph[i].edges[2].weight,
&myGraph[i].edges[3].dest, &myGraph[i].edges[3].weight,
&myGraph[i].edges[4].dest, &myGraph[i].edges[4].weight);
fclose(cfPtr);
cout << "Graph establish.\n"; |
8) Using 'prevPath' is more efficient than
stack, although C++ does come along with stack class. But nodes' shortest
routes often repeated (As there are only one 'shortest path'). Therefore better to create a custom 'stack' rather than
using C++ stack. By implementing 'prevPath', we only
create 'nodecount' number of nodes.

Fig. 3: Custom 'stack' inside using 'prevPath' for
Fig.1
7)
Nodes' ranking is the core of our algorithm. Bad nodes' ranking will
severely affect the algorithm performance.Therefore
we need a queue that sort nodes according to its ranking, so that some nodes
will have higher privilege over the rests. Those nodes that are more possible
to be the shortest path. We call it 'Priority Queue'. Higher priority nodes
will be extract first. It doesn't necessary to be minimum, can be either
maximum numbering, depend whether is source-to-destiny search or
destiny-to-source search.
C++ does come along with 'priority_queue' library. However we want a queue with sorting ability but not repeat.
Therefore, we need to add additioanl code to
the 'priority_queue'.
There
are two ways to initialize a priority_queue.
One is to push all the nodes into the queue, the other one push only source
node '0' into the queue. The latter one is better as to reduce repeated
nodes.
|
priority_queue <int, vector<int>, greater<int> > q; //
Here we define our priority_queue as minimum
extract first |
9) Here is the main operation of the algorithm
|
int top = -1, sum; < div >
q.pop();
q.push(myGraph[top].edges[i].dest); |
The
basic operation of the algorithm is edge relaxation: if there is an edge from u
to v, then the shortest known path from s to u can be extended to a
path from s to v by adding edge (u, v) at
the end. This path will have length d[u]+w(u,
v). If this is less than d[v], we can replace the current
value of d[v ] with the new value.
Edge relaxation is applied until all values d[v] represent the cost of the
shortest path from s to v. The algorithm is organized so that each edge (u,
v) is relaxed only once, when d[u] has reached its final value.
Always search from the top of the 'priority_queue',
where the node has the highest priority than the rest. Keep-on doing until 'priority_queue' is empty. When the nodes are removed
from the top of 'priority_queue', nodes are relaxed.
When d[w] != INFINITY and d[w] > d[u]+w(u, v), push u
back to the 'priority_queue'. Because hereby, the
shortest path is opposing axis x and y direction. (An
example of bad labelling)
There are many ways to interpret the method. This is one of the ways which I
put everything into one file.
Firstly, Visual C++ 'priority_queue'
nodes are repeatable. Therefore additional codes
are added to eliminate repeated computations. New variable 'top'
was added to record-down previous top queue. If "top" equal
to the current top queue, then the program skips the computation. Every time,
"top " will record-down the current top queue for the next
computation.
10) Print the shortest path out:
|
for(i=0; i<nodecount;
i++) {
}
cout << "Shortest distance is "
<< myGraph[i].shortestDistance <<
"\n\n"; } |
The disadvantage of this method is we need to calculate all the node's shortest
path from source in order to get to our destiny, since pc can't predict
which way is the shortest path. And we never know which way is the shortest
routes.
Following will illustrate how to avoid such problem, so that we can 'stop'
half-way through instead of searching all the nodes. The trick is to label the
nodes probably. This method wouldn't be so obvious in small graph. But will be
good in big graph.
Sample code:
Version 1: my13.cpp
Version 2: my11.cpp
Version 3: my14.cpp
Version 4: my16.cpp priority_queue1.cpp priority_queue1.h record_routes.cpp record_routes.h 1.txt
Version 5: my17.cpp
Version
6: In a graph, a node can have more than 5 edges. Therefore, save node’s
edges in list will make them space saving and expandable. ShortestPath18.cpp graph3.txt
Version 7: Save nodes using ‘harsh table / map’ instead of
List. ShortestPath19.cpp
graph1.txt
Version
8: Finding Shortest Path from nodes without priority, saves checklist as list
instead of priority queue. Before adding node_ID into
the list, check it does not exist in the list to avoid duplicated computations. ShortestPath20.cpp graph3.txt
In
‘graph3.txt’,
1st value in the pair is the next destiny node ID, 2nd
value is the path weight
Scenario
When live traffic / path weights are constantly changing. In
this scenario we update the graph every 1 second (‘timer1s’) up to
6 times / infinite times, and we compute the graph’s Shortest Path every
2 seconds (‘timer2s’) up to 3 times.
In c++, we declare the
‘timer1s’, ‘timer2s’ as separate threads. We declare
graph as a global object, accessible by all threads, including
‘timer1s’, ‘timer2s’. To allow multiple programs
threads to share the same graph but not at the same instance, we use mutex lock,
‘mutex_shortestPath’. Mutex lock is to
make sure at any instance only single thread is accessing or editing the shared
graph, avoiding program errors.
In this program, both threads ‘timer1s’,
‘timer2s’ will try to access the shared graph around the same
instance at 2nd seconds, 4th seconds and 6th
seconds.
ShortestPath_timers_mutex1.cpp graph3.txt
Self-Generated
Graph Code
For graph without discrete or distinct nodes, it is rational to make the graph
in matrix form.
Below
is the program to generate a matrix graph:
1) Create
the Structure Definitions for our nodes
|
struct Node { node *myGraph = new node[nodecount]; |
2)
Initialize the graph,
|
if(myGraph !=
NULL) { myGraph[i].prevPath = -1;
|
2) Below
is the program to auto generate the graph we want
|
i = 0; rightFrame:
myGraphLeft--; if(myGraphLeft <= 0) else
if( myGraph[i].y ==
-layer) {
i++; bottomFrame: myGraphLeft--; if(myGraphLeft <= 0)
i++; }
leftFrame:
if(myGraphLeft <= 0)
i++;
goto leftFrame; topFrame:
myGraphLeft--; if(myGraphLeft <= 0)
i++; stop: } }
|
The Relationship between
Labelling & Statistic, Possibility, Tendancy
Labeling in path search is so important that virtually supersede pure search
path itself. The reasons are very simple. Good labelling will significantly
reduce the search effects (to emphasize, very dramatically). On the
contrary, bad labelling will increase the workloads, and in turn suck-out all
the computing resource on doing meaningless, repeatedly, hopeless
searching.
As mention before, the worst case scenario will be the shortest path
always oppose our labelling direction (axis x and y ). It's
doesn't work well when we are dealing with small graphs. However,
when we are dealing with big graph, the advantage of systematic
labelling is obvious.
Labelling is virtually equal to defining nodes' priority. Therefore, the
important of labelling is undeniable. The following topics will discuss about
how to systematically do labelling.
Method 1: Virtual landscape rendering
Treat the graph as a map. Draw the contours in a high contrast colour or draw Landscape Heightfield line. Then use your
eye to do visual labelling.
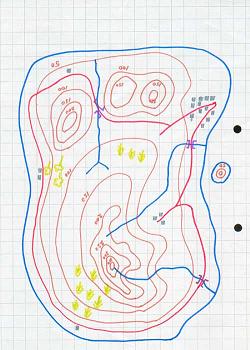
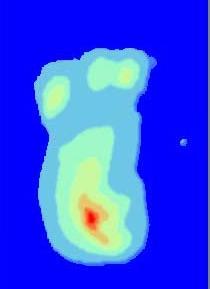
But obviously, this method is difficult
to implement. Edges' weights in most cases are not consistent (not
like geographical landscape), as result the virtual landscape we render might
be quite confusing. However, there still might have chances this method works
(e.g. country road map).
Method 2: Statistic
When we are dealing with big graph (a lot of nodes), we can use statistic to do
the labelling. As we mention before, a graph drawing should not be
confused with the graph itself (the abstract, non-graphical structure) as there
are several ways to structure the graph drawing. All that matters are which
vertices are connected to which others by how many edges and not the exact
layout. In practice it is often difficult to decide if two drawings represent
the same graph. Depending on the problem domain some layouts may be better
suited and easier to understand than others.
Should we take note that, estimation is just a prediction. It may not always
true and always able to label appropriately. Estimation is not equal to
shortest path itself.
There are 2 ways to represent a graph - List Structures & Matrix
Structures.
Although most of the times matrix structures only symbolically
representing there are connections between nodes in a graph. However to solve our estimated ranking problem, we will be
implementing matrix structures.
In matrix structures, there are few parameters will be used: radius, angle. To
simplify the problem, split nodes to layer-by-layer. In the most inner layers,
paths are always uncertain. In most outer layers, path will be
pointing to the destination. This is what called the tendency.
Use the radius length to represent layers, use angle to represent where the
nodes located. Therefore, geometric will be heavily utilized.
Inner layers are usually higher priority over the outer layers.
When all the edges' weight are close to the sample mean and sample standard
deviation, s is small
For this case, we can say all the nodes are almost alike.
This is the most simple form of graph we going to work with. It is an exponential
decay problem.
Here are some basic rules before we try to build our formula:
- Inner layer nodes always have higher
priority over outer layer
- Inner layers path tendencies are mostly uncertain
compare to outer layer
- In outer layer, path is clearly prone to
our destiny
- Trace the path tendency by their layers
& angles of the nodes' position
Path's tendencies in inner layers are uncertain. Therefore we will rank all the inner layers nodes highest
priority, 00~3600. In the outer the layers, path's
tendencies becoming more obvious. Hence we can narrow
down our angle.
General Equation:
exp(-b/cn)
Currently I try to find the these parameters.
Author: Lee Kin Seng
E-mail: lksark@hotmail.com
Copy Right. All right reserved.
![]()